


What is Hadoop?
Hadoop (ApacheTM Hadoop®) is an open-source system that was built to make it easier to deal with big data. It offers a way to access data in distributed environment among multiple clustered computers, manipuplate the data, and manage resources across the system assets (computer and network resource) that are involved. “Hadoop” generally consists of the four core components described below. Likewise, “Hadoop” is frequently utilized recprocally with “big data,” however it should not be like that. Hadoop is a system for working with enormous data. It is a piece of the big data ecosystem and including a lot more than Hadoop itself.
Hadoop is a distributed structure framework that ease to process huge data sets that dwell in clusters of computers. Since it is a framework, Hadoop is certainly not an individual technology or item. Rather, Hadoop is comprised of four main modules that are supported by a vast ecosystem of supporting advanced technologies and products. The modules are:
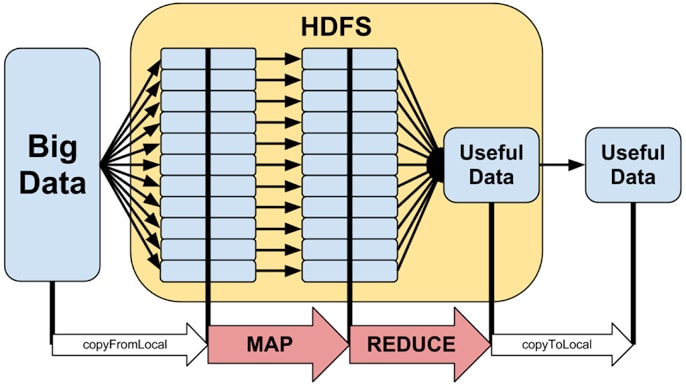
- Hadoop Distributed File System (HDFSTM) – Provides access to application data. Hadoop can also work with other file systems, including FTP, Amazon S3 and Windows Azure Storage Blobs (WASB), among others.
- Hadoop YARN – Provides the framework to schedule jobs and manage resources across the cluster that holds the data
- Hadoop MapReduce – A YARN-based parallel processing system for large data sets.
- Hadoop Common – A set of utilities that supports the three other core modules.
Big Data Services
- Evaluation of data
- Define Big Data Strategy
- Create a detailed plan for deployment
- Assess the current environment of technology
- Discuss plans for future expansion of big data environment
- Support business needs, recommend architecture and platform
- Monitoring of clusters of Hadoop
- Health checks and tests on Pre-Production
- Installation and Integration of Hadoop Clusters
- Hadoop Cluster configuration for optimum performance
- Develop data models, data ingestion procedures, and data pipeline management
- Analytics Optimization
- Data Visualization Solutions
- System optimization
- Security configuration
- Big Data Application Integration Services
- Hadoop monitoring, alerting and problems resolution


Big Data Landscape
- Hadoop distributions: Cloudera, Amazon EMR, Hortonworks
- Apache Hadoop ecosystem: Hive, YARN, Pig, Mahout, ZooKeeper, Spark
- Hadoop security: Kerberos, Apache LDAP
- NoSQL databases: Apache HBase, Apache Cassandra, MongoDB
- Data ingestion: Apache Sqoop
- Search engines: Apache Solr, Elasticsearch
- ETL tools: Pentaho, Talend
- Cloud: AWS, Microsoft Azure, Google Cloud Platform, Cloudera
- Machine-learning products: Spark MLlib, Mahout, GraphLab, R, Python ecosystem
- BI tools/visualization: Tableau and Zeppelin